Download Invoice Extractor
invoice-extractor.jsonDocument Input Examples
Here are some examples of the types of documents that this extractor can process.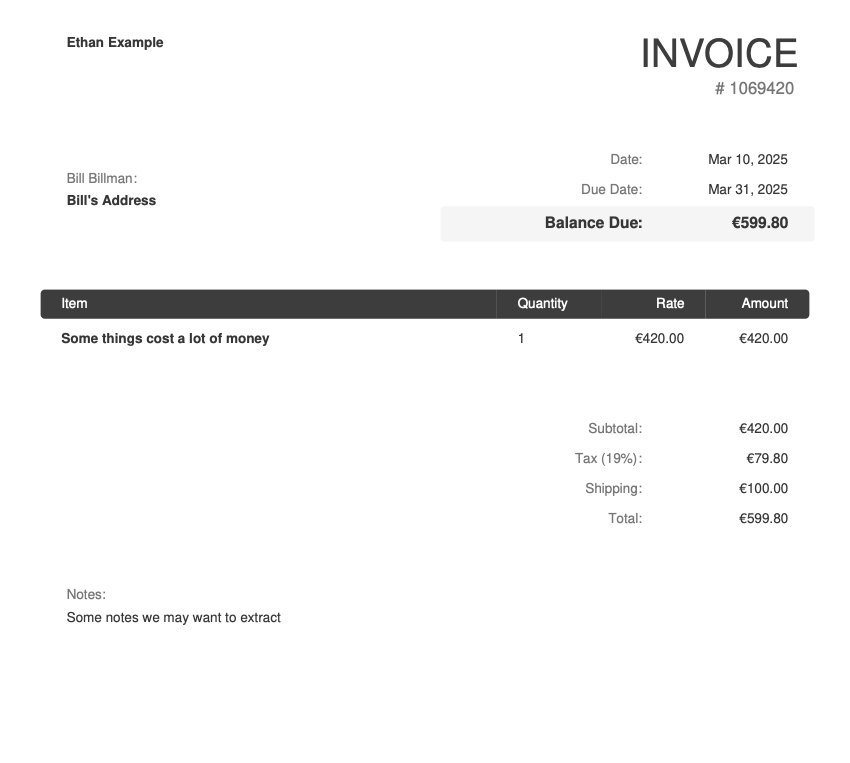
PDF Invoices
A lot of invoices are delivered as PDF files. These can be generated by accounting software or scanned from paper invoices.

Receipt Photos
Some invoices are only available as photos of receipts. These can be taken with a smartphone or a camera.
Scanned Paper Invoices
A lot of offices still receive paper invoices. These can be scanned and then processed by Data Wizard.
Example Output
This extractor will produce JSON data that looks like the following:Extractor
Here’s a template for an invoice extractor with some explanations for why some settings are chosen.JSON Schema
Here’s the example JSON schema to extract invoice data. It includes information about the invoice, seller, buyer, line items, total amounts, and payment details. The schema also contains validation rules for each field to ensure the extracted data is accurate and consistent.Show Invoice Schema
Show Invoice Schema
Extraction Strategy
Strategy: simple
You can use any of the strategies for invoice data.
It’s probably a good idea to get started with the simple strategy using a model with a large context window, for example google/gemini-2.0-flash.
LLM Recommendation: google/gemini-2.0-flash
This model has a large context window and is relatively cheap to use. It also has vision support, which is useful for scanned documents.
You can also use it’s lighter variant google/gemini-2.0-flash-lite if you want to save some costs.
Context Settings
Chunk Size: 75k
A chunk size of around 75.000 tokens should be enough to cover most invoices.
Include Text: true
Obviously, we’d want to include any text contents that are included in the invoice.
Include Embedded Images: false
We don’t need to include any of the images that are embedded in the files, as they are not relevant.
Include Page Screenshots: true
On the other hand, it makes sense to include page screenshots, as they give the LLM some more context about the location of certain text blocks.
It also allows the LLM to parse invoices that don’t have a text layer, like scanned documents or photos.
Mark Images with IDs: false
Since we’re not interested in assigning any images to data entities, we don’t need this setting.
Next Steps
Learn how to extract some data
Step by step guide to extract data from documents using Data Wizard.
Extractors
Learn how to define and configure data extraction tasks.
Strategies
Understand different data processing strategies.
LLM Provider Configuration
Set up your Large Language Model API keys.
Integration
Embed Data Wizard into other applications using iFrames or APIs.
Receipt photo by: kaboompics.com