Built-in Strategies
- Simple: Sends as much of the document as possible within the token limit to the LLM in a single call. Suitable for small documents.
- Sequential: Splits the document into smaller parts (based on the chunk size), processes each part sequentially, and includes the results of the previous extraction in the prompt for the next part. Maintains contextual continuity.
- Parallel: Splits the document into independent parts and processes each part in isolation. Suitable for multiple independent data points. Good for extracting data that aren’t interconnected across pages.
- Auto-Merging: Is the same as the sequential and parallel strategies, but additionally includes functionality that removes duplicate items by concatenating the items of the top-level properties and finally runs a final LLM call at the end to deduplicate the final results. This helps to make the models forget fewer entities if they have to make multiple calls.
- Double-Pass: Processes the document twice. On the first pass, it uses the parallel strategy, and on the second pass, it reviews and refines the first pass with the sequential strategy, taking both benefits for increased accuracy and efficiency. This one also supports auto-merging.
Simple
Simple
Sends as much of the document as possible within the token limit to the LLM in a single call. Suitable for small documents.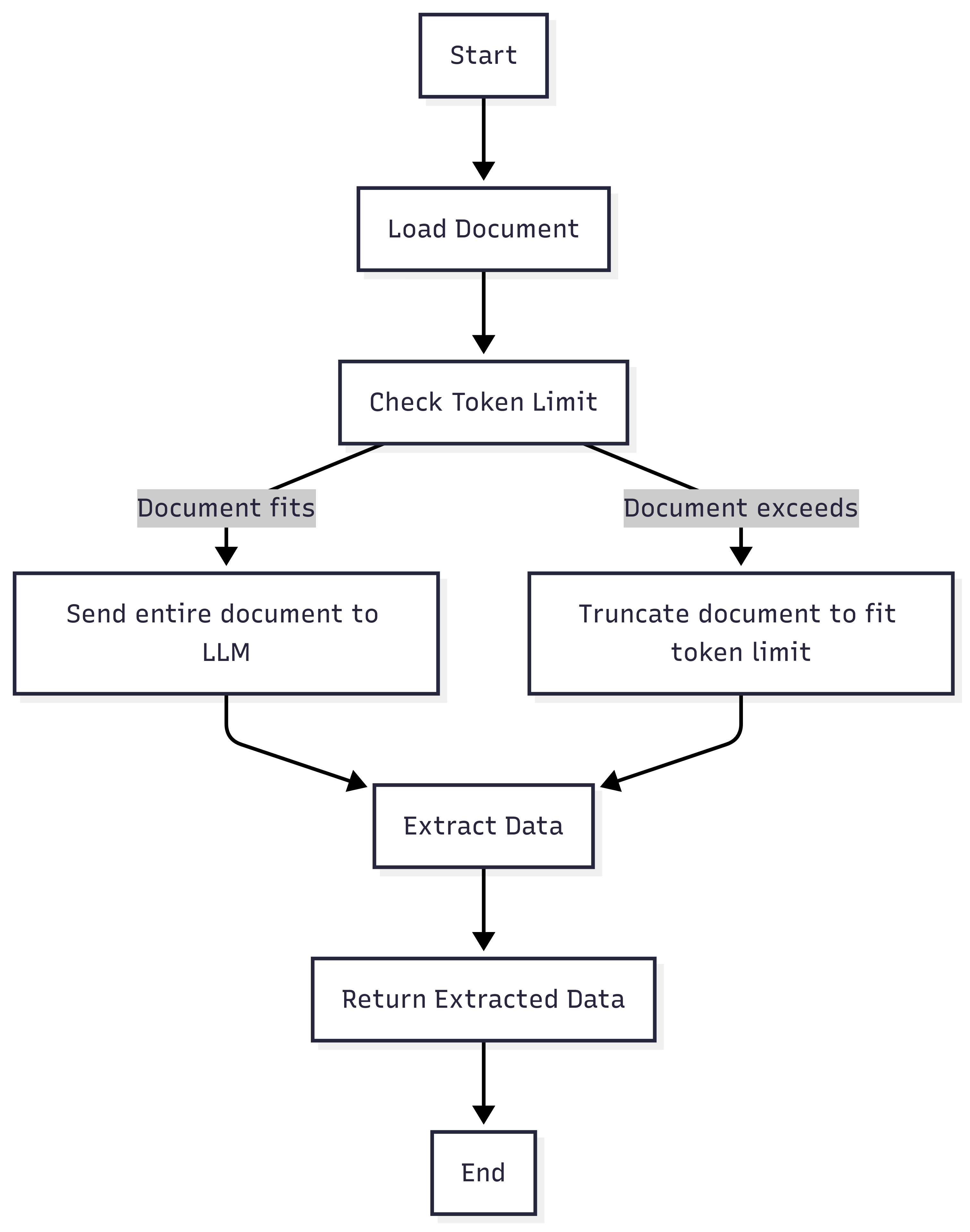
Sequential
Sequential
Splits the document into smaller parts (based on the chunk size), processes each part sequentially, and includes the results of the previous extraction in the prompt for the next part. Maintains contextual continuity.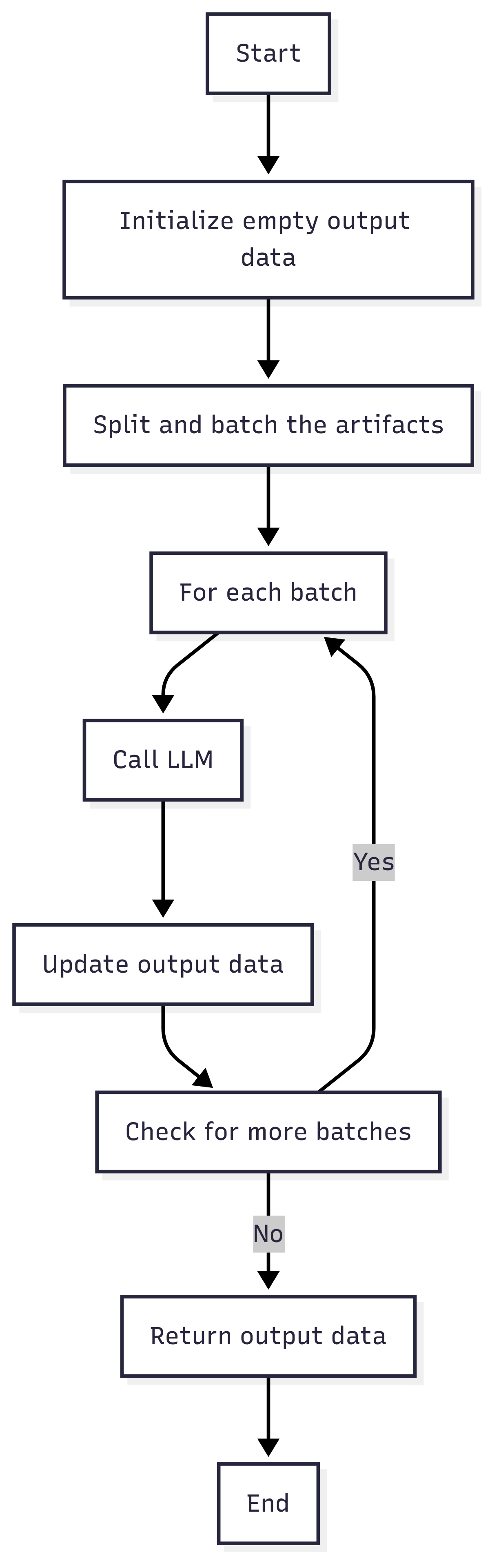
Parallel
Parallel
Splits the document into independent parts and processes each part in isolation. Suitable for multiple independent data points. Is good for extracting data that aren’t interconnected across pages.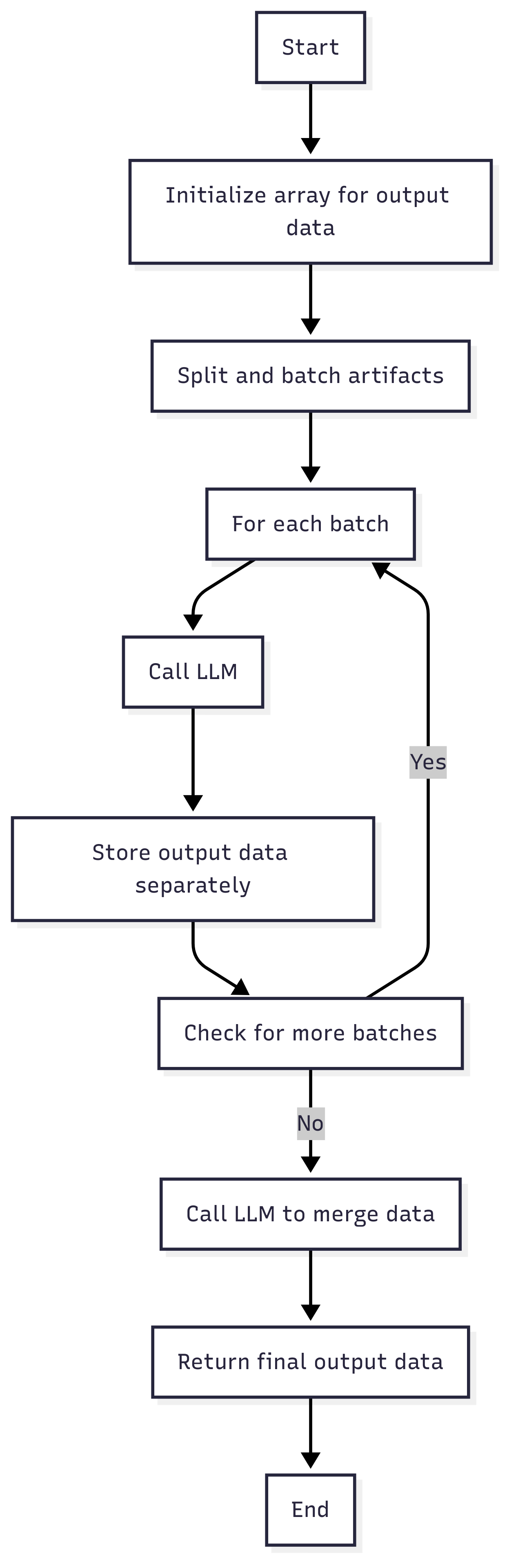
Sequential with Auto-Merging
Sequential with Auto-Merging
Splits the document into smaller parts (based on the chunk size), processes each part sequentially, and includes the results of the previous extraction in the prompt for the next part. Maintains contextual continuity. This one also supports auto merging.
Parallel with Auto-Merging
Parallel with Auto-Merging
Splits the document into independent parts and processes each part in isolation. Suitable for multiple independent data points. Is good for extracting data that aren’t interconnected across pages. This one also supports auto merging.
Double-Pass
Double-Pass
Processes the document twice. On the first pass, it uses the parallel strategy, and on the second pass, it reviews
and refines the first pass with the sequential strategy, taking both benefits for increased accuracy and efficiency. This one also supports auto merging.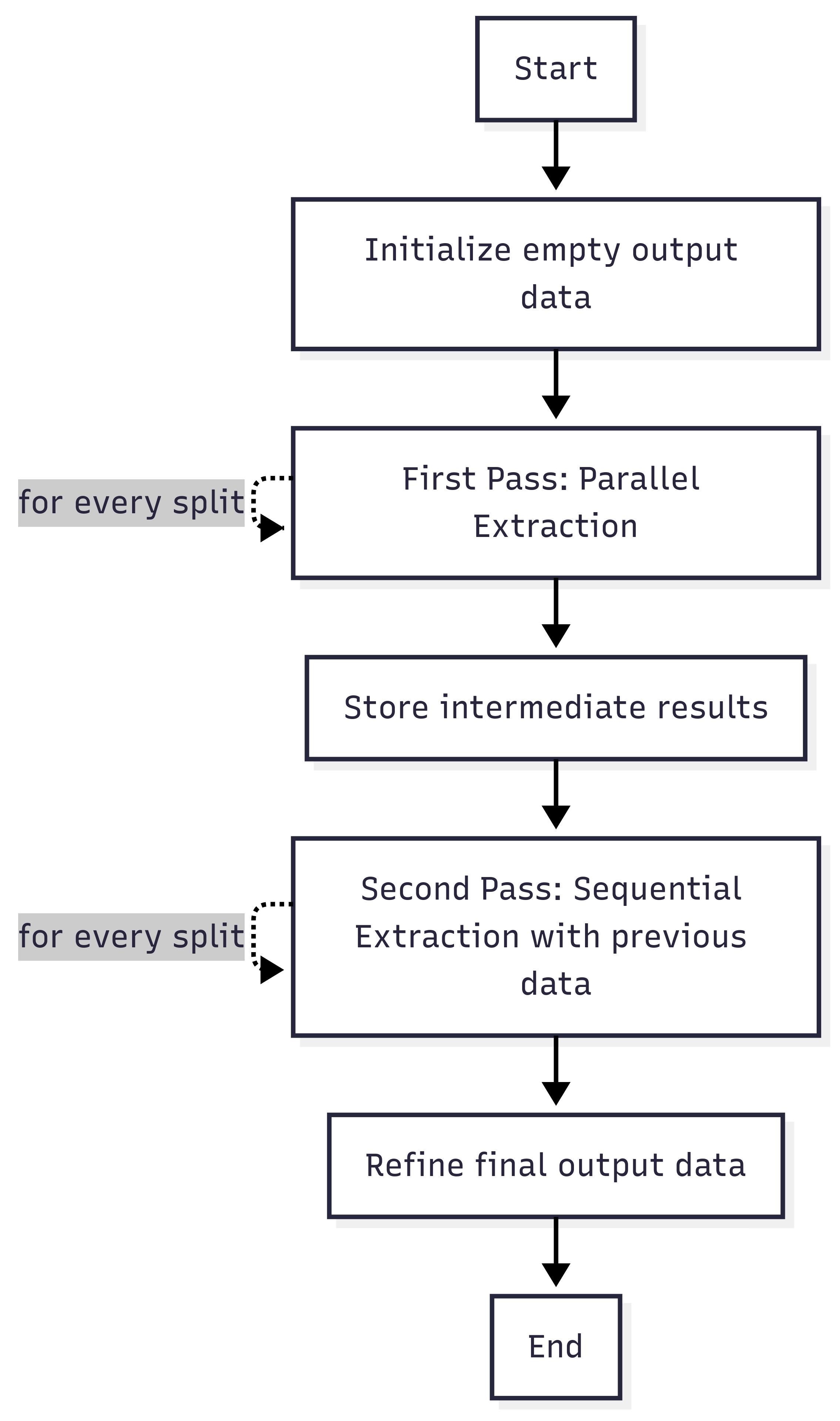
Strategy Options
Each strategy can be configured with a set of options:- Chunk Size: The maximum number of tokens to include in each LLM call.
- Include Text: Whether to include the raw text content of the document in the prompt.
- Include Embedded Images: Whether to include embedded images from the document in the prompt.
- Mark Embedded Images: Whether to mark embedded images in the document with identifiers.
- Include Page Images: Whether to include screenshots of the document pages in the prompt.
- Mark Page Images: Whether to mark page images with identifiers.
Custom Strategies
Learn how to build custom strategies for more control
You can create custom strategies to tailor the extraction process to your specific needs. Custom strategies allow you to define how the document is processed, how the LLM is interacted with, and how the results are merged.
Next Steps
Learn how to extract some data
Step by step guide to extract data from documents using Data Wizard.
Extractors
Learn how to define and configure data extraction tasks.
Strategies
Understand different data processing strategies.
LLM Provider Configuration
Set up your Large Language Model API keys.
Integration
Embed Data Wizard into other applications using iFrames or APIs.