Download Real Estate Extractor
real-estate-extractor.jsonDocument Input Examples
Here are some examples of the types of documents that this extractor can process.
PDF Exposés
Real estate exposés are often delivered as PDF files. These can be downloaded from real estate portals or provided by real estate agents.
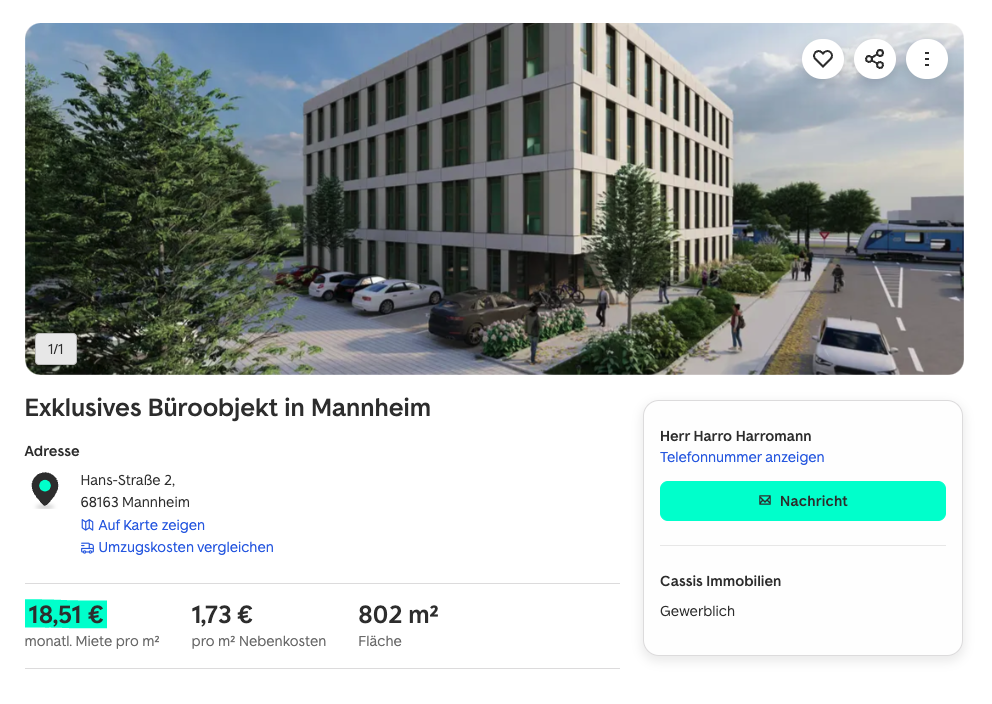
Web Listings
A lot of real estate data is available online. This extractor can help you get this information out of downloaded webpage data.
Example Output
This extractor will produce JSON data that looks like the following:Extractor
Here’s a template for a real estate exposé extractor with some explanations for why some settings are chosen.JSON Schema
Here’s the example JSON schema to extract real estate data. It includes information about the property, units, images and floorplans. The schema also contains validation rules for each field to ensure the extracted data is accurate and consistent.Show Real Estate Schema
Show Real Estate Schema
Extraction Strategy
Strategy: sequential-auto-merge
The sequential-auto-merge strategy is a good choice for real estate exposés because it processes the document sequentially, retaining context between pages. The auto-merging allows smaller entities like units or images to be merged together more effectively.
LLM Recommendation: google/gemini-2.0-flash
This model is a good choice for real estate exposés because of its vision capabilities and large context window. It is also relatively cheap to use and provides good performance for data extraction tasks. You can also use google/gemini-2.0-flash-lite for cost savings.
Context Settings
Chunk Size: 75k
A chunk size of around 75.000 tokens should be enough to cover most real estate exposés.
Include Text: true
Including text is essential for extracting textual information from the exposés.
Include Embedded Images: true
Including embedded images is crucial for associating images with specific units or the property itself. This allows the LLM to understand the context of the images and extract relevant data.
Include Page Screenshots: true
Page screenshots provide layout context, which is important for the LLM to understand the structure of the exposé and extract data accurately.
Mark Images with IDs: true
Marking images with IDs is necessary to associate images with data entities (property or units). This ensures that the extracted data includes references to the correct images.
Next Steps
Learn how to extract some data
Step by step guide to extract data from documents using Data Wizard.
Extractors
Learn how to define and configure data extraction tasks.
Strategies
Understand different data processing strategies.
LLM Provider Configuration
Set up your Large Language Model API keys.
Integration
Embed Data Wizard into other applications using iFrames or APIs.